LF10b
Serverdienste bereitstellen
und Administrationsaufgaben automatisieren
-
Dienste
-
Plattformen
-
Verfügbarkeit

https://johannesloetzsch.github.io/LF10b
Ziele gemäß Rahmenlehrplan
-
Serverdienste
bereitstellen,administrierenundüberwachen -
InformierenüberServerdiensteundPlattformen -
AuswahlgemäßKundenanforderungen- berücksichtigen von
Verfügbarkeit,Skalierbarkeit,Administrierbarkeit,WirtschaftlichkeitundSicherheit
- berücksichtigen von
-
PlanenderKonfigurationder ausgewählten Dienste und erstellenKonzepte zur Einrichtung,Aktualisierung,DatensicherungundÜberwachung -
Implementieren der Diensteunter Berücksichtigungbetrieblicher VorgabenundLizenzierungenTestverfahrenÜberwachungEmpfehlenKundenMaßnahmen bei kritischen ZuständenDokumentation von Ergebnissen
-
Automatisierung von Administrationsprozessenin Abhängigkeitkundenspezifischer Rahmenbedingungen,testenundoptimieren -
Reflektieren von LösungenundBeurteilenhinsichtlich Kundenanforderungen
Literatur
FiSi Abschlussprüfungen Teil 2
2021 - 2024
Lehrbuch FiSi LF10-12
„IT-Berufe Fachstufe II — Fachinformatiker/-in Fachrichtung Systemintegration — Lernfelder 10-12“
Westermann
- Auflage 2023 (Vorabversion)
ISBN 978-3-14-220108-5
Prüfungskatalog FiSi
„Prüfungskatalog für die IHK Abschlussprüfungen — Fachinformatiker Fachinformatikerin Fachrichtung Systemintegration — Verordnung über die Berufsausbildung zum Fachinformatiker/ zur Fachinformatikerin“
Zentralstelle für Prüfungsaufgaben der Industrie- und Handelskammern (ZPA) Nord-West
- Auflage 2024 (Stand 10/2024)
Prüfungsvorbereitung FiSi
„Prüfungsvorbereitung Aktuell — Teil 2 der gestreckten Abschlussprüfung Fachinformatiker/-in Systemintegration (nach der neuen Ausbildungsverordnung ab August 2020)“
Europa-Fachbuchreihe
- Auflage 2022
ISBN 978-3-7585-3169-9
Plan
80UE -> 2 doppelte + 3 einfache Noten
Zeitplan
gantt title LF10b August 2025 (6 Tage) dateFormat YYYY-MM-DD axisFormat %d.%m. section Mo 11.8. Einführung & Planung :2025-08-11, 1h Serverdienste (DHCP, DNS) :2025-08-11, 4h section Do 14.8. Serverdienste (NTP, LDAP, Mail, VoIP) :2025-08-14, 5h section Fr 15.8. Plattformen (Cloud, Virtualiserung), Auswahl :2025-08-15, 4h SOL Lernen für Klassenarbeit (+ Wiederholung LF9) :crit, 2025-08-15, 2h section Mo 18.8. Q&A, Wiederholung :2025-08-18, 6h section Mi 20.8. Klassenarbeit :crit, milestone, 2025-08-20, 2h Verfügbarkeit von Daten (Backup, RAID) :2025-08-20, 3h section Fr 22.8. Verfügbarkeit (TOM, Automatisierung, Monitoring) :2025-08-22, 4h SOL Wiederanlaufplan :crit, milestone, 2025-08-22, 2h
gantt title LF10b September 2025 (5 Tage) dateFormat YYYY-MM-DD axisFormat %d.%m. section Mo 22.9. Redundanz von Infrastruktur (USV, Link Aggregation, FHRP) :2025-09-22, 3h Wiederholung Verfügbarkeit, Q&A :2025-09-22, 3h section Di 23.9. Klassenarbeit :crit, milestone, 2025-09-23, 2h Vorstellung Projektpläne, Automatisierung :crit, 2025-09-23, 4h section Do 25.9. Praxis (Server aufsetzen) :2025-09-25, 5h section Mo 29.9. Praxis (Monitoring) :2025-09-29, 6h section Di 30.9. Praxis (Backup) :2025-09-30, 8h
gantt title LF10b November 2025 (3 Tage) dateFormat YYYY-MM-DD axisFormat %d.%m. section Mo 17.11. Praxis (Automatisierung) :2025-11-17, 5h section Di 18.11. Praxis (Testen, Optimieren) :2025-11-18, 6h section Fr 21.11. Vorführung Wiederanlauf + Präsentation :crit, 2025-11-21, 4h SOL Reflexion, Dokumentation :2025-11-21, 2h
Leistungsnachweise
-
Klassenarbeit Mi 20.8.2025 (doppelte Wertung, 90min, handschriftlich)
- erlaubte Hilfsmittel: Fact sheet (1 A4-Blatt, einseitig beschrieben)
- Inhalte
- Serverdienste
- Plattformen
- Cloud: Charakeristiken, Vor-/Nachteile, Service Models, Liefermodelle
- Virtualisierung: Hypervisor-Typen, Container-Arten
- (Auswahl gemäß Kundenanforderungen)
- Skalierbarkeit: scale up / scale out
- (Verfügbarkeit): Überblick Maßnahmen
-
Klassenarbeit Di 23.9.2025 (doppelte Wertung, 90min, handschriftlich)
- erlaubte Hilfsmittel: Fact sheet (1 A4-Blatt, einseitig beschrieben)
- Inhalte
- Verfügbarkeit: MTTF, MTBF, TOM
- USV: 3 Typen vergleichen
- RAID: Level vergleichen, Rechenaufgaben
- Datensicherung: RTO, RPO, WORM, 3-2-1, Generationenprinzip, Strategien, Rechenaufgaben
- Monitoring: Komponenten, Metriken, SMART, SNMP
- Auswahl gemäß Kundenanforderungen: Auswählen und Begründen im Bezug auf: Wirtschaftlichkeit, Skalierbarkeit, Administrierbarkeit, Sicherheit
- Verfügbarkeit: MTTF, MTBF, TOM
-
Projektplan (einfache Wertung)
- Insbesondere Wiederanlaufplan (SOL vom Fr 22.8.)
- Vortrag am Di 23.9.
-
Projektpräsentation Fr 21.11.2025
- fachlicher Projekterfolg (einfache Wertung)
- Umsetzung der zu optimierenden Ziele
- Demonstration Wiederanlauf, Einhaltung der RTO
- Mitarbeit (einfache Wertung)
- fachlicher Projekterfolg (einfache Wertung)
Serverdienste
❓❗ Was ist ein Dienst?
❓❗ Was ist ein Socket?
💬 Welche Dienste laufen auf ihren Geräten?
💻 Auf Unix-Shell mit SocketStat nachschauen:
ss -tul ## --tcp --udp ----listening ## Mehr Details (über die Prozesse/Dienste): ss -tulp ## --processes ss -tulpe ## --extended ss -tulpen ## --numeric
Well-Known-Ports
| Port | Dienst |
|---|---|
| 25 TCP | SMTP |
| 53 | DNS |
| 67,68 UDP | DHCP (BOOTP) |
| 80 TCP | HTTP |
| 123 UDP, (TCP) | NTP |
| 110 TCP | POP3 |
| 143 TCP | IMAP |
| 389 | LDAP |
| 636 | LDAPS |
| 443 TCP | HTTPS |
| 465 TCP | SMTPS |
| 993 TCP | IMAPS |
| 995 TCP | POP3s |
💻 Unix-Shell:
cat /etc/services
DHCP
Dynamic Host Configuration Protocol
RFC 2131, Weiterentwicklung von BOOTP
💬❗ Wofür wird DHCP benötigt?
Ermöglicht die Zuweisung der Netzwerkkonfiguration an Clients durch einen Server
- IP-Adresse, Netzmaske
- Default Gateway
- Name Server
- …
- „4-Way-Handshake“
- Adressvergabeverfahren bei DHCP
- DHCP-Relay
- Ausfallsicherheit
- Sicherheit
- SLAAC und DHCPv6
„4-Way-Handshake“
(Initiale Adresszuweisung) / „DORA“
💬 Wie bekommt ein neues Gerät im Netzwerk seine Konfiguration (vom DHCP-Server)?
❓❗ Welche DHCP-Nachrichten werden dafür in welcher Reihenfolge versendet?
❓❗ Wie finden Clients im Netzwerk den/die DHCP-Server?
sequenceDiagram
participant Client
participant Server
Note right of Server: UDP port 67
Client->>Server: 1. DISCOVER
Note left of Client: UDP port 68
Server->>Client: 2. OFFER
Client->>Client: Auswahl eines der Angebote
Client->>Server: 3. REQUEST
Server->>Client: 4. ACKNOWLEDGE
- DISCOVER
- UDP Broadcast an 255.255.255.255:67 (von Absenderadresse 0.0.0.0:68)
- OFFER
- Server in der Broadcastdomain schlagen dem Client eine IP vor
- REQUEST
- Client wählt einen der Server aus, der eine DHCPOFFER gesendet hat und „beantragt“ die vorgeschlagene IP
- ACKNOWLEDGE
- Server bestätigt Zuteilung und übermittelt zusätzliche Konfigurationsdaten
💻 Demo:
## Vorhandene Leases löschen ## (damit wir die initiale Adresszuweisung beobachten können) sudo rm /var/lib/dhcpcd/*.lease ## DHCP-Pakete beobachten sudo tcpdump -n port bootps -v | grep --color DHCP ## Mehr Details über den Inhalt des ACKNOWLEDGE sudo tcpdump -n port bootps -v | grep --color ACK -A 10
Adressvergabeverfahren bei DHCP
❓❗ Welche 3 Betriebsmodi (Adressvergabeverfahren) von DHCP gibt es?
Wie funktionieren sie?
Welche Vor- und Nachteile haben sie jeweils?
💬 Für welche Zwecke werden sie jeweils eingesetzt?
Manuelle/Statische Zuordnung (Static Allocation)
- basierend auf MAC
- nützlich, wenn Server eine Adresse per DHCP zugeteilt bekommen sollen
Automatisch (Automatic Allocaton)
- reserviert IP für MAC bei erster Vergabe
- Nachteil: keine neuen Clients möglich, wenn einmal gesamter Adressbereich vergeben
Dynamisch (Dynamic Allocation)
-
IP wird für Lease-Time („Leihdauer“) vergeben
-
nach Renewal-Time fragt Client den DHCP-Server per Unicast um Erneuerung der Lease-Time
-
nach Rebind-Time falls keine Antwort auf Renewal: Broadcast um Lease von einem anderen DHCP-Server erneuert zu bekommen
-
wenn Lease-Time abgelaufen: erneutes DHCP-Discover nötig
DHCP-Relay
❓❗ Was ist ein DHCP-Relay? Wofür wird es benötigt? Wie funktioniert es?
- erlaubt DHCP über Router hinweg
- im Relay wird Adresse des DHCP-Servers konfiguriert
- DHCP-Server benötigt separate Adress-Pools für jedes Subnetz
Ausfallsicherheit
❓❗ Wie können Verfügbarkeit und Skalierbarkeit erhöht werden?
Active-Passive-Failover
- Active-DHCP-Server synchronisiert seinen Status mit Passive-DHCP-Servern
- Bei Ausfall übernimmt ein Passive
Load-Balancing
- Scope (Adressbereich) wird aufgeteilt: Jeder Server ist für einen teil des Scopes Active
- Bei Ausfall übernimmt ein Passive den Scope des ausgefallenen Servers
Sicherheit
💬 Diskutieren Sie die Sicherheit von DHCP im Bezug auf
- Verfügbarkeit
- Integrität
- Vertraulichkeit
- Anonymität
Welche Gefahren gehen jeweils aus von
- Server
- Clients
- Dritten
Wie kann man sich schützen? Welche Grenzen haben diese Maßnahmen?
Maßnahmen
SLAAC und DHCPv6
„Stateless Address Auto Configuration“
RFC 4862 + RFC 8106
💬 Was wissen wir zu IPv6?
Wiederholung: IPv6-Subnetze
📝❗ FiSi AP2 Analyse Sommer 2024 Aufgabe 2e
❓❗ Was sind Link-Local-Adressen?
❓❗ Was ist ein Router Advertisement?
💬 Warum wird SLAAC als „Stateless“ bezeichnet?
- Welche Vor- und Nachteile bringt das mit sich?
sequenceDiagram
participant Client
participant Netz
participant Router
Client->>Client: 1. Link local Address
Client->>Netz: 2. Duplicate Address Detection
Client->>Router: 3. Router Solicitation
Router->>Client: 4. Router Advertisement
Note right of Client: Global Unicast Prefix,<br/>Gateway Address,<br/>DNS Server Address
Client->>Client: 5. Global Unicast Address
Client->>Netz: 6. Duplicate Address Detection
-
Client generiert eine Link-Local-Adresse (fe80::/64 z.B. aus der MAC)
-
Client prüft per Neighbor Discovery Protocol (ICMPv6), dass niemand anderes im Netz die gleiche Adresse nutzt
-
Client fragt mit Router-Solicitation-Nachricht nach Routern
-
Router antworten mit Router Advertisement
- beinhaltet Präfix, innerhalb dessen er Adressen anbietet
-
Client generiert Globale Adresse mit Präfix des Routers (und z.B. MAC oder Zufall)
-
Client prüft per NDP, dass niemand anderes im Netz die gleiche Adresse nutzt
💻 Welche MAC-,IPv4-,IPv6-Adressen haben wir?
- Welche der Adressen sind Link-Local und welche Global?
- Wie dauerhaft sind die Adressen?
- Wie wurden die Adressen konfiguriert/bezogen/generiert?
ip a | grep --color -e state -e ether -e inet
DHCPv6
💬 In welchem Verhältnis stehen SLAAC und DHCPv6?
📝❗ FiSi AP2 Analyse Sommer 2024 Aufgabe 1
💬 Welche Vor-/Nachteile haben die unterschiedlichen Adressvergabeverfahren?
📝❗ FiSi AP2 Analyse Sommer 2022 Aufgabe 1
DNS
Domain Name System
💬❗ Was ist DNS?
- Wofür wird es benötigt?
- Wie funktioniert es?
-
Verzeichnisdienst
- Client-/Server-Architektur
- hiearchisch, verteilter
-
„Telefonbuch“ des Internets
-
insbesondere für Auflösung von Domainnamen zu IP-Adressen
- …und andere Informationen begrenzter Datenmenge…
- die dezentral bereitgestellt werden
- die gecached werden dürfen
- …und andere Informationen begrenzter Datenmenge…
-
ersetztergänzt/etc/hosts(bzw.C:\Windows\System32\drivers\etc\hosts)
📝❗ FiSi AP2 Analyse Sommer 2023 Aufgabe 4
📝❗ FiSi AP2 Analyse Winter 2021 Aufgabe 4b-c
Inhaltsverzeichnis
- URI, URL, Domänennamen, Zonen
- Arten von Nameservern
- Resource Records und RR-Typen
- Sicherheit
- Vertiefende Informationen
URI, URL, Domänennamen, Zonen
URI
Uniform (Universal) Resource Identifier
Werden insbesondere im WWW für Hyperlinks verwendet
❓❗ Was sind URIs?
URIs sind einheitlich aufgebaut:
URI = scheme ":" hier-part [ "?" query ] [ "#" fragment ]
(RFC 3986)
URL, URN
flowchart TB URI --> URL URI --> URN URI --> data
Uniform Resource Locator identifizieren Ressourcen mittels Adresse
- Schema entspricht dem „primären Zugriffsmechanismus“ z.B.
http,https,ftp,file,mailto,tel - z.B.
https://de.wikipedia.org/wiki/Uniform_Resource_Locator,git://github.com/johannesloetzsch/LF10b.git
Uniform Resource Name identifiziert inhaltsgleiche Ressourcen anhand eines dauerhaft gültigen, eindeutigen Namens
- Schema sollte „urn“ sein
- Namensräume werden von IANA vergeben
- z.B. urn:ISBN:978-3-14-220108-5
Data-URLs
identifizierten Ressourcen direkt über ihren Inhalt
- müssen die Kodierung benennen
- z.B.
data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAAoAAAAKCAYAAACNMs+9AAAAXUlEQVQY073MvQ2CUADE8R90tOzgFkzgMg7gLs7BCDYmhD0sTV7F2Vi8EF5nuOpyH3/+rW4fhMvPDh3r4Stcwxxe4dbEh3co4ROedddXowmlyrYwtoj3sIRHc3S+vgySGhd7StmKAAAAAElFTkSuQmCC
FQDN
Fully Qualified Domain Name
- werden im
hier-partvon URIs verwendet - enden auf einen Punkt (der aber oft weggelassen wird)
DNS-Zonen
Teil des Domänenbaums, für den ein Nameserver zuständig ist

Root-Server, Root Hint
Arten von Nameservern
❓❗ Wie funktionieren die unterschiedlichen Arten von DNS-Servern?
- Warum ist es oft sinnvoll, einen vom ISP bereitgestellten Recursive Resolver und im eigenen Netz nur Forwarding Nameserver zu verwenden?
Beispiel: Was ist alles nötig, um eine IP für de.wikipedia.org. zu erhalten?
flowchart LR
classDef forwarding fill:#ccf
classDef recursive fill:#afa
classDef authoritative fill:#fc9
subgraph Client[localhost]
client_app{{Anwendung}}
client_os{{Betriebssystem}}
client_hosts["/etc/hosts"]
client_ns([Stub Resolver]):::forwarding
client_conf["/etc/resolv.conf\nnameserver 192.168.0.1"]
client_cache[Cache]
client_app -- 1a --> client_os
client_os -- 1b --> client_hosts
client_os -- 1c --> client_ns
client_ns -- 1d --> client_cache
client_ns -- 1e --> client_conf
end
subgraph Router[router.local\n192.168.0.1]
router_ns([Forwarding NS]):::forwarding
router_cache[Cache]
router_ns -- 3 --> router_cache
end
subgraph ISP[ns.isp.com]
isp_ns((Recursive NS)):::recursive
isp_cache[Cache]
isp_root_hint[Root Hint\na.root-servers.net]
isp_ns -- 5,7,9 --> isp_cache
isp_ns -- 6a --> isp_root_hint
end
root[(a.root-servers.net\nNS .\norg. 2756 IN NS a0.org.afilias-nst.info.)]:::authoritative
org[(a0.org.afilias-nst.info\nNS org.\nwikipedia.org. 12831 IN NS ns0.wikimedia.org.)]:::authoritative
wikipedia[(ns0.wikimedia.org\nNS wikipedia.org.\nde.wikipedia.org. 21434 IN CNAME dyna.wikimedia.org.\ndyna.wikimedia.org. 180 IN A 185.15.59.224)]:::authoritative
client_ns -- 2 --> router_ns
router_ns -- 4 --> isp_ns
isp_ns -- 6b --> root
isp_ns -- 8 --> org
isp_ns -- 10 --> wikipedia
6b: Welche Nameserver sind für die Zone `org.` zuständig?
org. 2756 IN NS a0.org.afilias-nst.info.
8: Welche Nameserver sind für die Zone `wikipedia.org.` zuständig?
wikipedia.org. 12831 IN NS ns0.wikimedia.org.
10: Unter welcher IP ist der Host `de.wikipedia.org.` erreichbar?
de.wikipedia.org. 21434 IN CNAME dyna.wikimedia.org.
dyna.wikimedia.org. 180 IN A 185.15.59.224
Authoritative
- Zuständig für eine Zone
- (Hoffentlich) unter Kontrolle des Domaininhabers
Recursive
- Resolved Anfragen rekursiv (Schrittweise vom Root-Server bis zur abgefragten Subdomain)
- fragt für alle Zonen die jeweiligen Authoritativen Nameserver
- Wird von ISPs bereitgestellt. Kann im eigenen Netz betrieben werden.
Forwarding (Caching, Stub-Resolver)
- Macht selbst keine rekursive Namensauflösung
- Antworted aus dem Cache wenn Eintrag vorhanden und nicht älter als TTL
- Wenn Eintrag nicht im Cache vorhanden: Fragt anderen Recursive (oder Forwarding) NS
- Üblicherweise von Routern und Betriebsystemen bereitgestellt.
❓❗ Was muss beachtet werden, wenn lokale Server mittels DNS genutzt werden?
Die Zonen von öffentlichen Domains sind über recursive Abfrage ausgehend von den Root-Servern erreichbar. Für lokale Netze können Authoritative Nameserver betrieben werden, die nicht öffentlich erreichbar sind. Damit Clients diese nutzen können, müssen diese die Nutzung des lokalen DNS-Servers konfigurieren.
📝❗ FiSi AP2 Analyse Sommer 2024 Aufgabe 2b
Resource Records und RR-Typen
Einträge (Zeilen) von Zonendateien
❓❗ Für welche Zwecke werden die folgenden RR-Typen benutzt?
Aufbau und Beispiele:
| name | ttl (Sekunden) | class | type | rdata |
|---|---|---|---|---|
| example.com. | 3600 | IN | A | 172.30.0.7 |
| example.com. | 3600 | IN | AAAA | 2600:1408:ec00:36::1736:7f24 |
| 7.0.30.172.in-addr.arpa. | PTR | example.com. | ||
| www.example.com. | IN | CNAME | example.com | |
| example.org. | IN | DNAME | example.com. | |
| example.com. | NS | nameserver.example.com. | ||
| @ | 3600 | IN | SOA | master.example.com. hostmaster.example.com. ( 2014031700 3600 1800 604800 600 ) |
| example.net. | IN | DNSKEY | ( 257 3 1 AQOW4333ZLdOHLRk+3Xe6RAaCQAOMhAVJu2Txqmk1Kyc13h69/wh1zhDk2jjqxsN6dVAFi16CUoynd7/EfaXdcjL ) | |
| nsf.example.org. | RRSIG | A 1 3 1000 20060616062444 ( 20060517062444 9927 example.org.mMBIXxXU6buN53GWHTPpwEbse4aR2gNI8rgsg9/x1We23K3gkO5DBjFdty27Fj4FMbQzg0uBuv9aFcPaMyILJg== ) | ||
| filiale1.example.org. | DS | 52037 1 1 378929E92D7DA04267EE87E802D75C5CA1B5D280 | ||
| whatever.example.com. | 3600 | IN | TXT | "Hello World" |
| _ldap._tcp.example.com. | 3600 | IN | SRV | 10 0 389 ldap01.example.com. |
| example.com. | 1800 | IN | MX | mailserver.example.com. |
| example.com. | 3600 | IN | SPF | "v=spf1 mx -all" |
| mail._domainkey.example.com | 6000 | IN | TXT | v=DKIM1; p=76E629F05F70 9EF665853333 EEC3F5ADE69A 2362BECE4065 8267AB2FC3CB 6CBE |
💻❗ Wo ist auf Unix-Servern konfiguriert, wie die Namensauflösung stattfinden soll?
cat /etc/resolv.conf /etc/hosts
💻❗ Wie kann man zum debuggen die IP-Adresse(n) zu einem Domainnamen auflösen?
dig afbb.de📝❗ FiSi AP2 Analyse Sommer 2024 Aufgabe 3ab
💻 Wie können für eine Domain alle Records recursiv resolved werden?
dig any afbb.de +trace
Sicherheit
💬❗ Diskutieren Sie die Sicherheit von DNS im Bezug auf
- Verfügbarkeit, Zensurresistenz
- Integrität, Authentizität
- Vertraulichkeit, Anonymität
Welche Gefahren gehen jeweils aus von
- DNS-Server
- Clients
- ISP
- Dritten
- Innerhalb der gleichen Broadcastdomain
- Außerhalb des eigenen Netzes
Wie kann man sich schützen? Welche Grenzen haben diese Maßnahmen?
DNS-Spoofing
- Angreifer kann sich mittels DHCP-Spoofing als DNS-Server des Netzwerks ausgeben
- Angreifer kann sich mittels IP-Spoofing als DNS-Server ausgeben
- Muss Antworten schneller als der korrekte DNS-Server ausliefern
=> kann mit DoS auf DNS-Server kombiniert werden
- Muss Antworten schneller als der korrekte DNS-Server ausliefern
DNS-Cache-Poisoning
- Angreifer kann DNS-Anfragen an Recursive oder Forwarding DNS-Server stellen und passende Antworten auf benötigte Rückfragen an nächsten Server selbst senden
- Wenn DNS-Server die Authentizität/Integrität der gefälschten Antworten nicht prüft:
- DNS-Server schreibt die manipulierten Daten in den Cache und liefern diese bis zur TTL bei künftigen Anfragen aus
Maßnahmen
DNSSEC
Domain Name System Security Extensions
- Authentizität wird mittels digitalen Signaturen abgesichert
DNSKEYResource Record beinhaltet öffentlichen Schlüssel der ZoneRRSIGResource Record enthält Signatur für zugehörigen DNS-Record- Eine Chain of Trust wird aufgebaut, indem in der Parent-Zone
- ein
DS(Delegation Signer) Resource Record mit dem Hash des Schlüssels der Zone abgelegt wird - die Parent-Zone selbst signiert wird
- der oberste Schlüssel der Kette muss dem Client vorab bekannt sein Vertrauensanker
- ein
❗ Vertraulichkeit ist bei DNSSEC nicht vorgesehen. DNS-Daten sind unverschlüsselt!
DNS over TLS (DoT)
💻 Beispiel Abfrage mit
dig:dig +tls @dns.digitale-gesellschaft.ch afbb.de
DNS over HTTPS (DoH)
- Anwendung fragt DNS-Server direkt anstatt über das Betriebssystem
Vertiefende Informationen

💡💬 Blog-Artikel zu Anfriffsszenario auf DNSSEC
NTP
Network Time Protocol
RFC 5905
💬💻 Wie spät ist es?
Und welcher Tag ist heute eigentlich???
man date watch -n.1 'date +%s; date --iso-8601=ns --utc; date --iso-8601=ns; date +"%d.%m.%Y %H:%M:%S,%N %Z (%A)"'💬 Warum brauchen wir eine „gemeinsame“ Zeit? Was bedeutet das?
Hierarchie nach „Stratum“

Funktionsweise und Genauigkeit
=> NTP überträgt die „genaue“ Zeit eines Zeitservers
=> Latenz wird gemessen
=> Jitter wird herausgemittelt
UTC, Unix-Timestamp, Zeitformate
| Bit | Era / Epoch | Seconds (Era Offset) | Fraction | Überlauf |
|---|---|---|---|---|
| 32bit | 1.1.1970 | 32bit signed | - | 2038 |
| 64bit | 1.1.1900 | 32bit unsigned | 32bit | 2036 |
| 128bit | 1.1.1900 Era 0 / 32bit signed | 32bit unsigned | 64bit | … |
💻 Beispiel: systemd-timesyncd
timedatectl timedatectl show-timesync --all
Sicherheit
💬 Welche Zusicherungen macht NTP bezüglich der Schutzziele
- Integrität
- Verfügbarkeit
💬 In welchen Fällen ist eine korrekte Systemzeit sicherheitsrelevant?
Maßnahmen
Verzeichnisdienste
ITU-T X.500
LDAP
Lightweight Directory Access Protocol

Standart-Attributtypen
oorganization
country
state
organizational unit
common name
surname
Group Policy Objects (GPO)
- Gruppenrichtlinien können 3 Zustände haben: „aktiviert“ / „deaktiviert“ / „nicht konfiguriert“
- Kumulative Vererbung innerhalb der Group Policy Hierarchy
- Ausnahme: No Override
Active Directory (AD)
Active Directory Domain Services
=> zentralisierte Windows-Domainverwaltung
Hauptkomponenten
- DNS
- LDAP
- Server Message Block (SMB) => Windows-Dateifreigabe
- Kerberos => Authentifizierung
(historisch gewachsen seit 1965/1968/1971)


D4a — Computer der TU Dresden zu dieser Zeit:
2000 Grundoperationen/Sekunde; 16,5 KByte Speicher

📝❗ FiSi AP2 Analyse Sommer 2022 Aufgabe 4
📝❗ FiSi AP2 Analyse Sommer 2023 Aufgabe 4
MUA, MTA/MDA
- Mail User Agent (Client)
- Mail Transfer Agent (SMTP-Server)
- Mail Delivery Agent (IMAP/POP3-Server)
💬❗ Wie unterscheiden sich POP3 und IMAP?
Welche der Protokolle will man verwenden?
=> Immer die Protokoll-Varianten, die auf „S“ enden 😉
(TLS nutzen)
MX-Record
Mail Exchange Resource Record (MX-RR)
=> sagt aus, unter welchem FQDN der SMTP-Server einer Domäne erreichbar ist
💻❗ Beispiel
dig any afbb.de;; ANSWER SECTION: […] afbb.de. 21600 IN MX 1 afbb-de.mail.protection.outlook.com. afbb.de. 600 IN TXT "v=spf1 include:spf.protection.outlook.com include:spf.emailsignatures365.com include:mx-smtp-out.mtl-servers.de -all"dig any afbb-de.mail.protection.outlook.com;; ANSWER SECTION: afbb-de.mail.protection.outlook.com. 10 IN AAAA 2a01:111:f403:ca04::5
📝💬❗ FiSi AP2 Analyse Sommer 2023 Aufgabe 4ba
Aufbau einer E-Mail (Kodierung) und Header
RFC 5322
=> nur Zeichen des 7-Bit-ASCII-Zeichensatzes => Base64
=> MIME (Multipurpose Internet Mail Extensions)
Beispiel:
From: <adam@example.org>
To: <eva@example.org>
Subject: Umlaute dank MIME
MIME-Version: 1.0
Content-Type: text/plain; charset=iso-8859-15
Content-Transfer-Encoding: 8bit
Body
Content-Type-Header definiert den MIME-Media-Typ des Body:
Sicherheit
💬❗ Wo werden Mails gespeichert?
- Welche Server haben zusätzlich während des Versands Zugriff?
💬❗ Diskutieren Sie die Sicherheit von E-Mail im Bezug auf
- Verfügbarkeit
- Integrität, Authentizität
- Vertraulichkeit, Anonymität
Welche Gefahren gehen jeweils aus von
- Servern (MTA, MDA, NS, …, DC)
- Clients (MUA, Client-Arbeitsumgebung)
- Dritten
- Innentäter aus dem Unternehmen (Kollegen, Kunden, Gäste, …)
- Botnetzen (Spammer, (Spear-)Phishing, Würmer)
- …
Wie kann man sich schützen?
Welche Grenzen haben die jeweiligen Maßnahmen?
💬 Was ist ein (offenes) SMTP-Relay?
Wofür werden Smarthosts benötigt?
Welche Herausforderung hat man, wenn man im eigenen Heimnetz (z.B. DSL-Anschluss) einen Mailserver betreiben möchte?
Wie ist das, wenn man im Rechenzentrum einen Mailserver betreiben will?
💬❗ Was ist E-Mail-Spoofing?
SPF
Sender Policy Framework
(seit 2003)
DNS-Record, der definiert welche MTAs für eine Domain Mails versenden dürfen (Im Gegensatz zum MX-Record, der die zuständigen Empfänger definiert). Die Empfänger können per SPF-Record herausfinden, ob der Absender gültig zu sein scheint. [1] [2] [3]

📝💬❗ FiSi AP2 Analyse Sommer 2023 Aufgabe 4bb
[1] SPF ist nicht Final Ultimate Solution to the Spam Problem (FUSSP)
[2] Kritik and SPF
DKIM
DomainKey Identified Mail
RFC 6376 (seit 2006, immer noch nicht von allen Servern unterstützt)
=> Absender-Authentifizierung , diesmal basierend auf asymmetrischer Kryptographie
- Der SMTP-Server erzeugt ein asymmetrisches Schlüsselpaar
- der Private Schlüssel wird geheim gehalten (!*💬)
- der Öffentliche Schlüssel wird als TXT-Record per DNS veröffentlicht
- Mail-Body und vom Sender ausgewählte Header-Zeilen werden gehashed und dann signiert
- Hash und Signatur werden Base64 kodiert in Mail-Header „DKIM-Signature“ versendet
- Der Empfänger einer Mail kann eine Verifikation durchführen, indem er:
- den Hash selbst neu berechnet und prüft
- den öffentlichen Schlüssel der Absender-Domain per DNS (!*💬) abfragt (DKIM TXT-RR)
- die Signatur über den Hash mittels des öffentlichen Schlüssels prüft

Da DNS als Vertrauensanker/PKI verwendet wird, sollte (!*) DNSSEC eingesetzt werden.
💬❗ Inwieweit hilft DKIM gegen Spam und Phishing?
💬❗ Wie sollte mit Mails umgegangen werden, die nicht DKIM-signiert sind?
DMARK
Domain-based Message Authentication, Reporting and Conformance
=> im DNS wird für Absender-Domain eine DMARC-Richtlinie veröffentlicht, ob/wie SPF und DKIM eingesetzt werden
💬 Welche Probleme mit DMARC gibt es?
Verschlüsselung (und Ende-zu-Ende-Signaturen)
Verbindungsorientiert (TLS) vs. Ende-zu-Ende (S/MIME)
Web-of-Trust (PGP) vs. PKI (X.509)
💻❗ MUA „sicher“ konfigurieren
 pEp
pEp
pretty Easy privacy
 CAcert
CAcert
=> nichtkommerzielle Certification Authority
VoIP, Videokonferenzsysteme, WebRTC und QoS
Voice over IP (VoIP) => Internettelefonie
📝💬❗ FiSi AP2 Analyse Sommer 2022 Aufgabe 4

SIP/SIPS
Session Initiation Protocol
RFC 3261, RFC 5630
=> Signalisierungsprotokoll (zum Verbindungsaufbau)
RTP
Real-Time Transport Protocol
RFC 3550
=> Echtzeitübertragung (*💬) von Multimedia-Datenströme (Audio, Video, Text, …)
SRTP
Secure Real-Time Transport Protocol
RFC 3711
=> Verbindungsverschlüsselte Variante von RTP
WebRTC
Web Real-Time Communication
(seit 2011)
=> W3C-/IETF-Standart, der mittlerweile von allen verbreiteten Browsern unterstützt wird
- basiert auf HTML5 und JavaScript
- Verschlüsselung über DTLS und SRTP im Standart vorgeschrieben 🤗
- Peer-to-Peer
- NAT traversal mittels ICE/STUN/TURN
QoS
Quality of Service
=> Dienstgüte
📝💬❗ FiSi AP2 Analyse Sommer 2022 Aufgabe 4e
Herausforderung:
- Nur in Netzsegmenten möglich, die man selber kontrolliert (nicht im Internet)
- Netzneutralität
ToS
Type of Service
=> 8-bit Feld im IP-Header, die unterschiedlich interpretiert werden
IEEE 802.1p
=> Priorisierung von Datenpaketen nach Priorisierungslevel
RTCP
RealTime Control Protocol
=> kann mit RTP eingesetzt werden, um QoS-Parameter auszuhandeln
Fax nach Umstellung auf VoIP (FoIP)
📝💬❗ FiSi AP2 Analyse Sommer 2022 Aufgabe 4f
Plattformen
💬❗ Welche Plattformen gibt es? Wie unterscheiden sie sich?
- Verschiedene Rechnerarchitekturen (RISC/CISC)
- Verschiedene Betriebssysteme
- On-Premises vs. Cloudanbieter
💬 Welche Kriterien für eine Auswahl gemäß Kundenanforderungen sollten bei der Entscheidung für eine Plattform berücksichtigt werden?
📝❗ FiSi AP2 Konzeption Sommer 2024 Aufgabe 1b
📝❗ FiSi AP2 Konzeption Winter 2024 Aufgabe 1b
- Technische Schulden und Vendor Lock-in
- Cloud
- On-Premises
💬❗ Welche langfristigen Folgen kann eine Entscheidung für eine Plattform bedeuten?
Technische Schulden und Vendor Lock-in
💬 Inwieweit sollten offene Standarts bei der Auswahl einer Plattform bzw. eines Anbieters berücksichtigt werden?
Cloud
📝❗ FiSi AP2 Analyse Winter 2021 Aufgabe 1
📝❗ FiSi AP2 Analyse Winter 2022 Aufgabe 1a
📝❗ FiSi AP2 Analyse Winter 2023 Aufgabe 1a
📝❗ FiSi AP2 Konzeption Sommer 2024 Aufgabe 1
📝❗ FiSi AP2 Konzeption Winter 2024 Aufgabe 1
Charakeristiken von Cloud-Computing
🇺🇸 💬 Welche Cloud-Computing Charakteristiken wurden vom NIST definiert?
On-demand Self-service
=> Selbstbedienung
Broad Network Access
=> mit Standardmechanismen über das Netzwerk erreichbar
Resource Pooling
=> Ressourcen des Anbieters werden zusammengefasst und bedienen mehrere Nutzer nach dem Mandantenprinzip
Rapid Elasticity
=> Leistung wird dynamisch bereitgestellt/freigegeben und kann bedarfsgerecht skalieren => Aus Nutzersicht scheinen die verfügbaren Ressourcen unbegrenzt
Measured Service
=> Genutzte Ressoucen werden gesteuert und überwacht. Die Bezahlung erfolgt nach dem Prinzip pay-per-use
Service Models (Dienstleistungsmodelle)
flowchart TB CloudService --> SaaS CloudService --> PaaS CloudService --> IaaS
SaaS
Software as a Service
PaaS
Platform as a Service
z.B. DB, „AWS Container Service“ „AWS Kubernetes Service“
IaaS
Infrastructure as a Service
z.B. virtuelle private Server (VPS), „AWS Elastic Compute Cloud2“ (EC2)

💬 Welche Cloud-Plattformen/-Lösungen/-Produkte sollte man kennen?
Auf welchen Standarts basieren sie und welche Alternativen gibt es?
Liefermodelle (Bereitstellungsarten)
💬❗ Welche Liefermodelle werden unterschieden?
Public Cloud
=> Was wir klassisch meinen, wenn wir von Cloud sprechen
Private Cloud
=> „Cloud-Umgebung“, die ausschließlich für eine Organisation oder ein Unternehmen betrieben wird
Hybrid Cloud, Community Cloud, Virtual Private Cloud, Multicloud, …

💡💬 Vortrag: „Sollen wir in die Cloud gehen?“
📝❗ FiSi AP2 Konzeption Sommer 2024 Aufgabe 1a
📝❗ FiSi AP2 Konzeption Winter 2024 Aufgabe 1a
On-Premises
=> „in den eigenen Räumlichkeiten“
Cluster
„Rechnerverbund“ / „Schwarm“ / „Farm“
Architektur aus vernetzten Servern („Knoten“), die zusammenwirken um einen gemeinsamen Dienst zu erbringen.
Werden üblicherweise eingesetzt um Kapazität (Compute + Storage) und Verfügbarkeit im benötigten Maß gewährleisten zu können.
Basieren auf dem Prinzip der Horizontalen Skalierung (scale out)
Virtualisierung
📝❗ FiSi AP2 Analyse Winter 2023 Aufgabe 1b
Einführung
Virtualisierung erlaubt mehrere Systeme auf der selben physischen Hardware (Hostsystem) gleichzeitig auszuführen. Aus Sicht der Gast-Systeme verhält sich die virtualisierte Umgebung gleich oder zumindest ähnlich wie die physische Hardware.
Virtuelle Maschinen (VMs) basieren auf der Virtualisierung (Multiplexing) jeder einzelnen Hardwarekomponente (Prozessorvirtualisierung, Speichervirtualisierung, Netzwerkvirtualisierung, …).
Die Implementierung kann jeweils als Emulation in Software (flexibel aber ineffizient), in Hardware oder einer Kombination von beidem erfolgen. Moderne Prozessoren verfügen über geeignete Erweiterungen um Virtualisierung in Hardware effizient zu unterstützen. Die Kontrolle erfolgt üblicherweise in Software durch den sogenannten Hypervisor (auch Virtual-Machine-Monitor genannt), welcher das Betriebssystems des Hosts ergänzt (Typ-2) oder ersetzt (Typ-1).
Für viele Anwendungsfälle ist eine Isolation von Systemen erwünscht, jedoch keine Virtualisierung von vollständigen Maschinen notwendig.Für diesen Fall können leichtgewichtige Virtual Environments (VE) verwendet werden, deren Funktionalität direkt vom Betriebssystem ohne zusätzlichen Hypervisor bereitgestellt wird. Historisch sind Jails wichtig. Heute sind Container nach dem OCI-Standart, insbesondere Docker sehr verbreitet.
Hypervisor-Typen und Container-Arten
flowchart TB Virtualisierung --> VirtualMachine VirtualMachine --> Typ-1-Hypervisor VirtualMachine --> Typ-2-Hypervisor Virtualisierung --> VirtualEnvironment VirtualEnvironment --> Systemcontainer VirtualEnvironment --> Anwendungscontainer
| Typ-1-Hypervisor | Typ-2-Hypervisor | Systemcontainer | Anwendungscontainer | |
|---|---|---|---|---|
| Hypervisor | (native/bare-metal: Hypervisor ersetzt/ist Host-Kernel) | (hosted: Hypervisor läuft auf dem Host-OS) | Teil der Host-OS-Funktionalität | Host-OS + Container-Dienst |
| Gast | Als Gast-Betriebssystem muss ein speziell angepasster Kernel verwendet werden, der vom Hypervisor weiß und diesen nutzt. | Beliebiges OS kann als Gast verwendet werden. Aus Sicht des Gast-Kernels sieht die VM wie Hardware aus. | Linux-Distribution in chroot-Umgebung auf Host-Kernel (Ohne Gast-Kernel) | einzelne isolierte Anwendung |
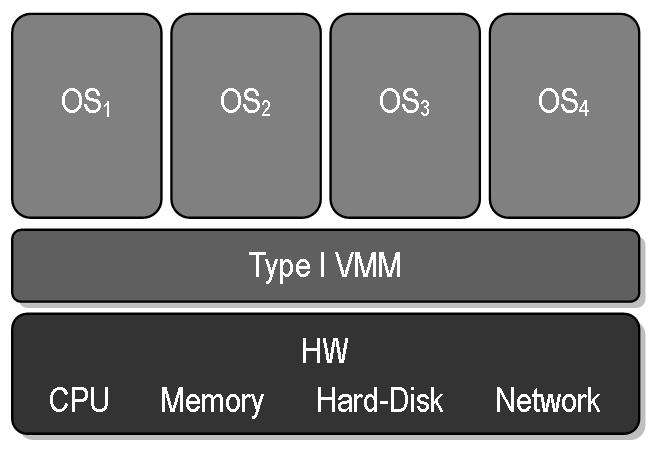 | 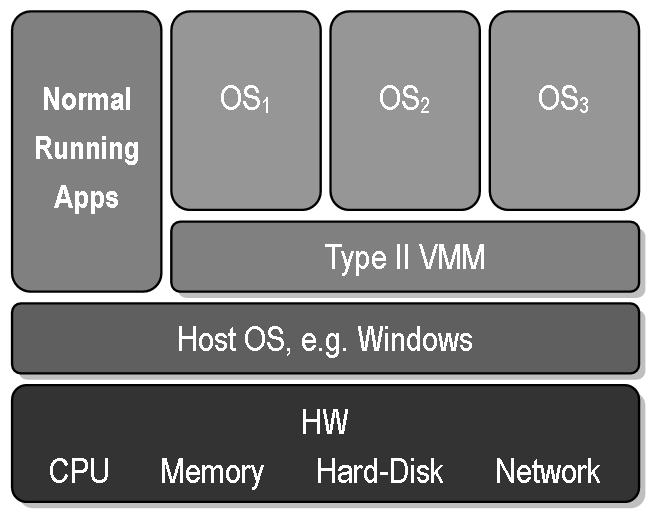 | |||
| Eigenes Init-System | Ja | Ja | Ja | Nein |
| Isolation | ++ | +++ | + | + |
| Performance | ++ | + | +++ | +++ |
| Leichtgewichtig | + | + | ++ | +++ |
| Beispiel | XEN, Hyper-V | KVM, VirtualBox | LXC, FreeBSDjail | Docker, Podman |
| Einsatzgebiete | dedizierter Virtualisierungsserver | VMs auf bestehendem OS ermöglichen | leichtgewichtige VEs für viele parallele Linux-Systeme | leichtgewichtige VEs für isolierte Anwendungen |
📝❗ FiSi AP2 Analyse Sommer 2022 Aufgabe 4
Einsatzzwecke
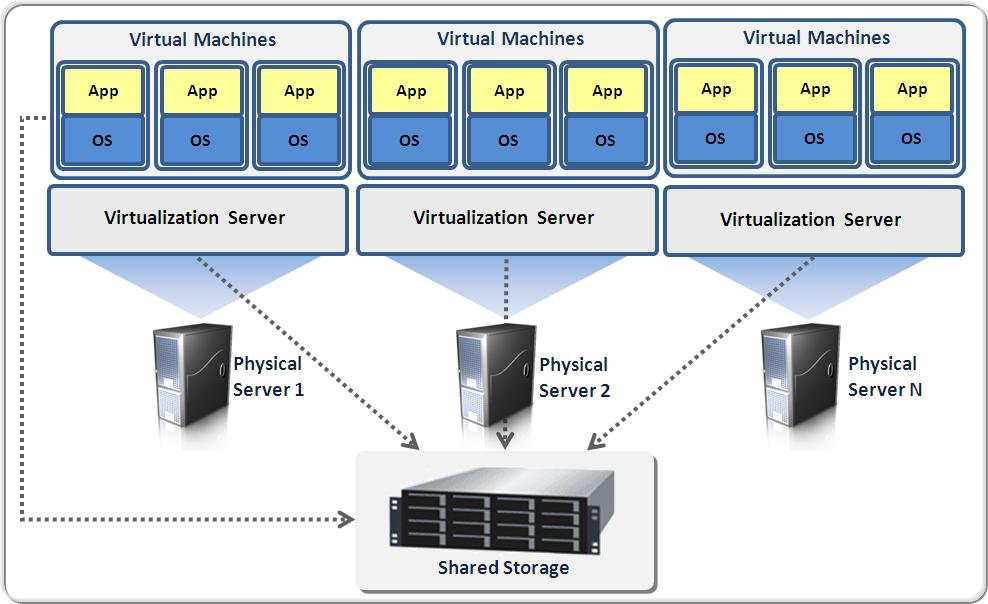
- Isolation
- => Administrierbarkeit durch Modularisierung (divide and conquer)
- Sicherheit (*💬)
- Hardware-Einsparung (bessere Auslastung der Server durch dynamische Lastverteilung)
- Wirtschaftlichkeit
- Green-IT
- Migration / Live migration
- Während geplanter Wartung
- Wenn mehr Ressourcen benötigt werden => dynamische Skalierung
- Failover bei Ausfällen
- günstiger Betrieb von Diensten im Cluster
- Verfügbarkeit durch Redundanz
- Skalierbarkeit
Potentielle Nachteile
- Effizienzverlust durch Virtualisierungsoverhead
- Lastspitzen in einer VM können je nach Ressourcentrennung Einfluss auf andere VMs haben
- Herausforderung für Datenschutz/-sicherheit => Sandbox escape
- Fragen bezüglich Lizenzierung
- Zusatzaufwand (wenn kein geeignetes Automatiserungskonzept vorhanden)
Docker
Hallo Welt
cd examples/docker/hallo
cat Dockerfile
docker build -t hallo .
docker images
docker run hallo
reales Praxisbeispiel: Hedegedoc
cd examples/docker/hedgedoc
less Dockerfile
docker build -t hedgedoc .
docker images
docker run -p 3000:3000 hedgedoc
mehrere Anwendungscontainer: Prometheus
cd examples/docker/prometheus
docker network create -d bridge monitoring
docker run --name=nodeexporter -d --net=monitoring -p 9100:9100 -v "/:/host:ro,rslave" --pid="host" quay.io/prometheus/node-exporter:latest --path.rootfs=/host
docker run --name=prometheus -d --net=monitoring -p 9090:9090 -v ./prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
docker run --name=grafana -d --net=monitoring -p 3000:3000 grafana/grafana-enterprise
compose.yaml
Informieren und Auswahl
Auswahlkriterien
flowchart TB Kriterien --> Kundenabhängig Kundenabhängig --> Anforderungsanalyse Kriterien --> Anbieterabhängig Anbieterabhängig --> Machbarkeitsanalyse Kriterien --> Problemabhängig Problemabhängig --> Problemanalyse
=> Lastenheft
=> Pflichtenheft
Wirtschaftlichkeit
💬 In welchem Verhältnis stehen Wirtschaftlichkeit und andere Anforderungen?
Wirtschaftlichkeit=Erträge/Aufwendungen
Erträge werden durch das bereitstellen von Funktionalität erwirtschaftet.
Automatisierung bietet großes Potential im Senken von Aufwendungen. Es ermöglicht zuvor variable Kosten in nahezu Fixkosten zu wandeln. Automatisierungspotential ist in vielen Fällen der Grund, Prozesse zu digitalisieren.
Durch Skalierbarkeit können die fixen Stückkosten gesenkt und damit die Wirtschaftlichkeit erhöht werden (Fixkostendegression).
Als Massengut verkäufliche IT-Produkte können aufgrund von Skaleneffekten (Economies of scale) besonders effizient von Anbietern erbracht werden, welche sich auf Hyperscale computing spezialisiert haben.
Kleinere Unternehmen und Startups sind eher dann konkurrenzfähig, wenn sie individuelle Dienstleistungen entsprechend variabler Kundenanforderungen anbieten. Dazu zählen Beratung, Support, Integration, Anpassungen, …
Als Massengut verkäufliche IT-Produkte (IaaS, PaaS) und Standardsoftware als SaaS können aufgrund von Skaleneffekten (Economies of scale) besonders effizient von Anbietern erbracht werden, welche sich auf Hyperscale computing spezialisiert haben.
Kleinere Unternehmen und Startups sind eher dann konkurenzfähig, wenn sie individuelle Dienstleistungen entsprechend variabler Kundenanforderungen anbieten. Dazu zählen Individualsoftware, Beratung, Support, Integration, Anpassungen, …
flowchart TB Wirtschaftlichkeit --> Funktionalität --> Sicherheit Wirtschaftlichkeit --> Automatisierung Wirtschaftlichkeit --> Skalierbarkeit Verfügbarkeit --> Redundanz Redundanz --> Clustering Administrierbarkeit --> Automatisierung Sicherheit --> Safety Sicherheit --> Security Sicherheit --> Automatisierung Sicherheit --> Administrierbarkeit Safety --> Verfügbarkeit Security --> Verfügbarkeit Skalierbarkeit --> Automatisierung Skalierbarkeit --> Clustering Automatisierung <==> Clustering
Die gute Administrierbarkeit von Systemen wird durch ein geeignetes Maß an Automatisierung begünstigt. Beide sind Voraussetzung für Skalierbarkeit und Sicherheit.
Sicherheit ist eine wichtige Funktionalität, die den Wert eines Produktes mitbestimmt. Sicherheit benötigt Investitionen, lohnt sich aber durch Reduktion von Risiken. Schutzbedarfs- und Risikoanalyse können bei der Beurteilung helfen, welches Maß an Risikobehandlung „good enough“ ist.
Sicherheit wird in Safety (Betriebssicherheit) und Security (Schutz vor Angreifern) unterschieden. Beide sind von geeigneter Automatisierung abhängig.
Verfügbarkeit ist ein Schutzziel (Grundwert) der IT-Sicherheit. Die technische Maßnahmen zur Erhöhung der Verfügbarkeit basieren meist auf Redundanz.
Um Redundanz effektiv und wirtschaftlich bereitzustellen, sollten Komponenten möglichst nicht als Standby, sondern in einer Aktiv/Aktiv-Konfiguration mit Load Balancing betrieben werden.
Cluster-Lösungen zeichnen sich durch einen hohen Automatisierungsgrad aus und sind für die Zwecke Hochverfügbarkeit und Skalierbarkeit optimiert.
Skalierbarkeit
❓❗ Welche Arten von Skalierbarkeit gibt es und in und welche davon möchten Sie in welchen Fällen nutzen?
📝❗ FiSi AP2 Konzeption Sommer 2023 Aufgabe 2b
Horizontale Skalierung (scale out) vs Vertikale Skalierung (scale up)
=> Wenn „doppelt so viel“ benötigt wird, kostet das meist deutlich mehr als das zweifache
(bei scale up)…
=> Warum nicht einfach „zweimal das einfache“ nutzen?
=> scale out! => commercial off-the-shelf
- Beispiele für Umsetzung von horizontaler Skalierungslösungen
- Einschränkung durch Kommunikation + SharedMemory
- Kurz und Knapp:
- CAP-Theorem




Beispiele für Umsetzung von horizontaler Skalierungslösungen
flowchart TB Skalierbarkeit --> Cluster Skalierbarkeit --> LoadBalancer Skalierbarkeit --> Anycast/Multicast
Einschränkung durch Kommunikation + SharedMemory
Grenzen der horizontale Skalierung:
- Verteilte Dateisysteme
- Verteilte Datenbankmanagementsysteme
- Uniform Memory Access (Symmetrisches Multiprozessorsystem) vs Non-Uniform Memory Access (Asymmetrisches Multiprocessing)
Die Parallele Effizienz von Algorithmen ist problemabhängig und ein eigenes Fachgebiet.
Für Details bitte die passende Vorlesung besuchen, die richtigen Bücher lesen, …
Oder sich von jemandem beraten lassen, der sich damit auskennt ;)
Probleme: Kommunikationsoverhead, Konsistenz, Cache-Kohärenz

Kurz und Knapp:
=> Wann immer möglich ist Horizontale Skalierung (scale out) meist deutlich günstiger als Vertikale Skalierung (scale up).
=> Horizontale Skalierung funktioniert dann gut, wenn:
- das Problem gut parallelisierbar ist
(Teilprobleme lose gekoppelt sind) - die Softwarearchitektur für diese Art von Problemen geeignet optimiert ist
=> daher ist schlaue Auswahl der Lösung sehr wichtig
=> Es gibt jedoch leider auch Herausforderungen, bei denen eine horizontale Skalierung schwierig bis unmöglich ist
CAP-Theorem
Das CAP-Theorem besagt, dass es in einem verteilten System unmöglich ist, gleichzeitig die folgenden drei Eigenschaften zu garantieren:
- Consistency (Konsistenz)
- Availability (Verfügbarkeit => akzeptabler Antwortzeiten)
- Partition Tolerance (Ausfalltoleranz)
Jedes Systemdesign kann nur maximal zwei der drei Eigenschaften garantieren.

AP
Consistency + Availability + Partition Tolerance
Wenn Verfügbarkeit und Ausfalltoleranz wichtig sind, kann keine Konstistenz gewährleistet werden.
Für viele Dienste reicht Eventual consistency.
Für diesen Anwendungsfall sind NoSQL-Datenbanken optimiert.
In diese Kategorie fallen die meisten „Cloud“-Dienste bzw. Internet-Dienste.
z.B. DNS, NTP, Mail, …
=> horizontale Skalierung ist möglich => kostengünstige Lösungen möglich
CP
Consistency + Availability + Partition Tolerance
z.B. Banking-Anwendungen
Konsistenz ist essenziell und es muss davon ausgegangen werden, dass einzelne Komponenten ausfallen.
=> In dem Fall wird akzeptiert, dass Dienste mal nicht zur Verfügung stehen (es darf länger dauern)
CA
Consistency + Availability + Partition Tolerance
Relationale Datenbankmanagementsysteme (RDBMS) sollen Konsistent sein (ACID). Wenn auch Verfügbarkeit benötigt wird (meistens), dann ist keine Partitionstoleranz möglich. Wenn einzelne (Primary) Knoten ausfallen, muss ein anderer Knoten die Funktion übernehmen können und dafür den letzten Zuständ des Primary kennen. Dafür muss der Primary jeden Schreibzugriff an seine potentiellen Ersatzknoten kommunizieren, bevor eine Transaktion als erfolgreich commited abgeschlossen werden kann.
Wir benötigen also schnelle Kommunikation und Cache-Kohärenz zwischen den Knoten…
=> Scale Up
=> teuer
Administrierbarkeit
- Snowflakeserver vs Konfigurationsmanagementsysteme
- Automatisierung
- Vergleich verrschiedenen Automatierungslösungen
- Mobile-Device-Management (MDM)
Snowflakeserver vs Konfigurationsmanagementsysteme
❓ Was wird unter einem Snowflakeserver verstanden?
flowchart TB Automatisierung --> Verfügbarkeit --> Administrierbarkeit Automatisierung --> Skalierbarkeit --> Administrierbarkeit Automatisierung --> Wirtschaftlichkeit --> Administrierbarkeit Automatisierung --> Sicherheit --> Administrierbarkeit Automatisierung --> Administrierbarkeit Versionskontrolle --> Administrierbarkeit Versionskontrolle --> ChangeRequestManagement --> Administrierbarkeit Versionskontrolle --> Rollback --> Administrierbarkeit Versionskontrolle --> Kooperation --> Administrierbarkeit Versionskontrolle --> CICD --> Administrierbarkeit
Automatisierung
Setup, Updates, Wiederherstellung
💬❗ Welche Lösungen kennen Sie, um alle auf ihen Systemen installierte Software regelmäßig mit Sicherheitsupdates zu versorgen?
❓❗ Was muss bei der Installation berücksichtigt werden, um horizontale Skalierbarkeit wirtschaftlich gewährleisten zu können?
💬❗ Wie können Sie Automatisierungslösungen zur Notfallwiederherstellung einsetzen?
Konfigurationsmanagement
❓❗ Welche Vorteile haben Konfigurationsmanagementsysteme?
❓❗ Wie unterscheiden sich imperative und deklarative Systemverwaltung?
💬 Welche KM-Werkzeuge kennen Sie?
Vergleich verrschiedenen Automatierungslösungen
| Image | Skripte | Konfigurationsmanagementsysteme | Docker | NixOS | NixOS+Flake | |
|---|---|---|---|---|---|---|
| Konfigurationsanpassung | Imperativ + neues Image erstellen | Variablen/Skript anpassen + ausführen | Playbook anpassen + ausführen | Dockerfile anpassen + (re)build | configuration.nix anpassen + rebuild | flake.nix anpassen + rebuild |
| Wiederherstellung möglich | ja | ja | ja | ja | ja | ja |
| Wiederherstellung+Updates | in separatem Schritt | ja | ja | ja (Updateschritt oder Rebuild) | ja differenziell | ja differenziell |
| Änderungen können per Versionskontrolle verwaltet werden -> Changemanagement | (nein) | ja | ja | ja | ja | ja |
| Inkrementelle/Differenzielle Änderungen | nein | ja | ja | ja | ja | ja |
| Imperativ/Deklarativ | (Imperativ) | Imperativ | (Deklarativ) | (Deklarativ)(basiert auf Imperativen Anweisungen) | Deklarativ | Deklarativ |
| Idempotente Änderungen | nein | aufwändig/fehleranfällig | (ja) (aufwändig/fehleranfällig) | ja | ja | ja |
| Kombinierbarkeit mehrerer Konfigurationen | nein | (ja, aber fehleranfällig) | (ja) | (ja, Baum von Konfigurationen) | ja | ja |
| sauberes Deinstallieren | nein (nur durch vollständige Wiederherstellung) | aufwändig/fehleranfällig | (fehleranfällig) | ja | ja | ja |
| Reproduzierbarkeit | nur auf Stand vorhandener Images | nein (sehr schwer+fehleranfällig zu implementieren) | (nein) | schwer Seiteneffekte zu vermeiden | (ja) wenn Inputs gelockt sind | ja |
Mobile-Device-Management (MDM)
📝❗ FiSi AP2 Analyse Sommer 2025 Aufgabe 3
Sicherheit
ErwartetungswertSchaden = ∑ WahrscheinlichkeitSchadenseintritt * SchadenshöheSchadensfall
Schutzziele und Maßnahmen
flowchart TB Sicherheit --> Verfügbarkeit -..-> Redundanz Sicherheit --> Vertraulichkeit -..-> Verschlüsselung Sicherheit --> Integrität -..-> Signaturen+Authentifizierung
Vertraulichkeit
flowchart TB Vertraulichkeit -..-> Verschlüsselung Verschlüsselung --> Datenträgerverschlüsselung Verschlüsselung --> Transportverschlüsselung Transportverschlüsselung --> Verbindungsverschlüsselung Transportverschlüsselung --> Ende-zu-Ende-Verschlüsselung
Integrität
flowchart TB Integrität -..-> Signaturen+Authentifizierung Signaturen+Authentifizierung --> TrustedBoot+TPM Signaturen+Authentifizierung --> SoftwareSignaturen SoftwareSignaturen --> SCM SoftwareSignaturen --> Paketierung SoftwareSignaturen --> Distribution Signaturen+Authentifizierung --> SingleSignOn+MultiFaktorAuth
Verfügbarkeit == Ausfallsicherheit
flowchart TB Verfügbarkeit --> Redundanz Redundanz --> Hardware Hardware --> Cluster Hardware --> USV Redundanz --> Netzwerk --> Topologie Netzwerk --> LinkAggregation Netzwerk --> FHRP Redundanz --> Services Services --> Architektur Services --> Deployments --> Staging Deployments --> BlueGreen Redundanz --> Daten Daten --> DistributedDB Daten --> Raid Daten --> Backups Verfügbarkeit --> OrganisatorischeMaßnahmen OrganisatorischeMaßnahmen --> Monitoring OrganisatorischeMaßnahmen --> Wiederanlaufkonzepte OrganisatorischeMaßnahmen --> Automatisierung Automatisierung --> Skalierbarkeit+Wirtschaftlichkeit Skalierbarkeit+Wirtschaftlichkeit Automatisierung --> Wiederanlauf Automatisierung --> ChangeManagement Automatisierung --> Rollback
=> Redundanz
USV
RAID
Netzwerk
Redundanz von Services
💬❗ Welche Maßnahmen zur Erhöhung der Verfügbarkeit kennen Sie?
Welchen Beitrag können diese Maßnahmen zur Skalierbarkeit leisten?
flowchart TB Redundanz --> LoadBalancing LoadBalancing --> Anycast+ColdSpare Redundanz --> ms[Master/Slave] ms --> HotSpare+Heartbeat
z.B.
- DNS
- DHCP
- Datenbanken
- Webserver
- Router
Link Aggregation
IEEE 802.3ad, IEEE 802.1AX
„Bonding“
=> Redundanz => Ausfallsicherheit
=> erhöhter Durchsatz
Verschiedene Funktionen von Link Aggregation:
Wikipedia
- Round Robin
- Active Backup
- XOR....

First Hop Redundancy Protocols (FHRP)
Deployments
Staging-Umgebung
💬❗ Welche Bereitstellungsumgebungen kennen Sie?
Blue Green Deployments
❓❗ Was versteht man unter einem Blue Green Deployment?
TOM
💬❗ Welche Technischen und Organisatorischen Maßnahmen sind erforderlich um Verfügbarkeit für ein System zu gewährleisten?
USV
Unterbrechungsfreie Stromversorgung
Störungen im Stromnetz
- Stromausfall
- Spannungsspitzen
- Spannungsschwankungen, Störspannung, Spannungsverzerrung
- Frequenzschwankungen, Frequenzstörungen
Klassifizierung
💬❗ Welche Arten von USV kennen Sie? Wie unterscheiden diese sich?
Welche Vor- und Nachteile (jeweils mindestens 2) haben sie im Vergleich?
📝❗ FiSi AP2 Konzeption Sommer 2023 Aufgabe 2
„Prüfungsvorbereitung Fachinformatiker Systemintegration“ 2.5.7. (Seite 71)
flowchart TB USV --> Offline -..-> VFD USV --> Netzinteraktiv -..-> VI USV --> Online -..-> VFI
Offline-USV (VFD)
=> Voltage and Frequency Dependent

Netzinteraktive-USV (VI)
=> Voltage Independent (but frequency dependent)

Online-USV (VFI)
=> Voltage and Frequency Independent

Vergleich
| Offline | Netzinteraktiv | Online | |
|---|---|---|---|
| VFD | VI | VFI | |
| Umschaltzeit | ~10ms | ~2-4ms | 0ms |
| Eigenbedarf (Leerlauf) | ~5W | ~15W | ~85W |
| Wirkungsgrad (unter Last) | ~100% | ~95% | |
| Kosten | min | max |
Praxiserfahrung
💡 Wie ist die Lebensdauer der Akkus?
- Temperatur (im Serverraum)
- Wartung, Testen, Messen, Überwachen
💡 Was passiert wenn die Akkus und der Diesel des Generators alle sind?
💡💬 Was muss ich bei der Wartung beachten?
- Sind meine Server alle „Reboot Safe“?
Redundanz in Netzwerken
❓❗ Welche Maßnahmen zur Bereitstellung von Redundanz in Netzwerken kennen Sie?
Link Aggregation
IEEE 802.3ad, IEEE 802.1AX
„Bonding“
=> Redundanz => Ausfallsicherheit
=> erhöhter Durchsatz
First Hop Redundancy Protocols (FHRP)
„Prüfungsvorbereitung Fachinformatiker Systemintegration“ 2.8.10. (Seite 104)
flowchart TB RedundanteRouter --> IETF --> VRRP RedundanteRouter --> Cisco Cisco --> GLBR Cisco --> HSRP
-
verwenden Nachrichten um Status der Router auszutauschen
-
verwenden virtuele MAC-Adresse
-
verwenden virtuelle IP-Adresse
-
erlauben LoadBalancing zwischen Routern (außer HSRP)
Storage
Netzwerkspeicher
DAS
Direct Attached Storage
=> (per Ethernet) an einen einzelnen Rechner angeschlossene Festplatten ohne Netzwerk

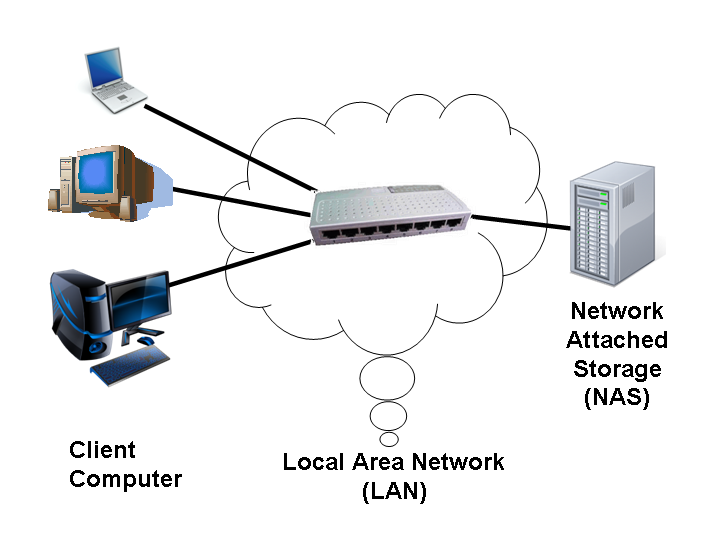
NAS
Network Attached Storage
=> „netzgebundener Speicher“
=> Dateibasiert
SAN
Storage Area Network
=> Speichernetzwerk für hohe Verfügbarkeit und Performance
=> z.B. mittels Fibre Channel
=> Blockbasiert

Optimierung
Cluster-/Blockgröße
❓❗ Welchen Einfluss hat die Clustergröße auf Performance und Datenkapazität?
Deduplizierung
❓❗ Was ist Deduplizierung und wie funktioniert sie?
Welche Vor- und Nachteile kann sie haben?
Was sind typische Einsatzzwecke?
Kompression
❓❗ Erklären Sie den Unterschied zwischen verlustfreier und verlustbehafteter Datenkompression und benennen Sie typische Anwendungsbeispiele.
RAID
redundant array of independent disks
redundant array of inexpensive disks
📝❗ FiSi AP2 Konzeption Winter 2021 Aufgabe 3
📝❗ FiSi AP2 Konzeption Sommer 2022 Aufgabe 1
📝❗ FiSi AP2 Konzeption Winter 2023 Aufgabe 4c
📝❗ FiSi AP2 Konzeption Sommer 2024 Aufgabe 4
📝❗ FiSi AP2 Konzeption Winter 2024 Aufgabe 3
💬 Welche RAID-Level kennen Sie?
| RAID level | Disks | Redundanz |
|---|---|---|
| RAID0 (striping) / JBOD | n >= 2 | 0 |
| RAID1 (mirroring) | n >= 2 | n-1 |
| RAID5 (single parity) | n >= 3 | 1 |
| RAID6 (double parity) | n >= 4 | 2 |
| RAID01 (mirroring of striping) | n >= 4 | n/2 (bei 2fachem mirroring) |
| RAID10 (spriping of mirroring) | n >= 4 | n/2 (bei 2fachem mirroring) |
❓❗ Wieviele Platten dürfen jeweils maximal ausfallen bevor Daten verloren gehen?
❓❗ Wieviele der Platten stehen als Nettokapazität zur Verfügung?
❓❗ Wie wirkt sicht die Redundanz bei den verschiedenen RAID-leveln auf die Lese- und Schreibgeschwindigkeit im Vergleich aus?






„Prüfungsvorbereitung Fachinformatiker Systemintegration“ 2.6.4. (Seite 66)
💬 Welche Vor- und Nachteile haben Software-/Hardware-Raidcontroller?
Datensicherung
- Ziele / Einordnung
- Datensicherungskonzept / Disaster Recovery
- Prinzipien / Ansätze
- Backupstrategien
- Archivbit
- Prüfungsaufgaben
- Lösungen / Tools
Ziele / Einordnung
💬 Für welche Ereignisse (elementare Gefährdungen) werden Backups benötigt?
💬❗ Ersetzen RAID-Lösungen und Snapshots von Dateisystemen die Notwendigkeit von Backups?
❓❗ Was ist der Unterschied zwischen einem Backup und einem Archiv?
Datensicherungskonzept / Disaster Recovery
RTO
Recovery Time Objective
RPO
Recovery Point Objective

📝❗ FiSi AP2 Konzeption Sommer 2023 Aufgabe 4c
Prinzipien / Ansätze
WORM
write once read many
=> Sicherstellen, dass Backups nicht vom zu sichernden System überschrieben werden können
3-2-1-Regel
- 3 Kopien der Daten (einschließlich Original) => 2 Backupkopien
- 2 verschiedene Medientypen
- 1 Offsite Kopie
💬 Warum sind Off-site-Backups wichtig?

Generationenprinzip
(Großvater-Vater-Sohn-Prinzip)
=> mehrere Versionen/Generationen von Backups müssen existieren
z.B.
- tägliche Sicherung („Sohn“)
- wöchentliche Sicherung („Vater“)
- monatliche Sicherung („Großvater“)
Backupstrategien
📝❗ FiSi AP2 Konzeption Sommer 2023 Aufgabe 4a
Vollbackups
Differenzielle Backups
=> Differenz zum letzten Vollbackup
Inkrementelle Backups
=> Inkrement seit letztem (Inkrementellen) Backup
Archivbit
💬 Welche unterschiedlichen Möglichkeiten gibt es, mittels derer Backup-Tools entscheiden können, ob Dateien sich seit dem letzten Backup geändert haben?
Welche Vor-/Nachteile haben diese Methoden?
Archivbit:
- Kennzeichnet neue und modifizierte Dateien. Wird bei Schreiboperationen gesetzt.
- Wird zurückgesetzt nach:
- Vollbackups
- Inkrementellen Backups
- Wird nicht zurückgesetzt nach:
- Differenziellen Backups
📝❗ FiSi AP2 Konzeption Winter 2022 Aufgabe 3b
Prüfungsaufgaben
📝❗ FiSi AP2 Konzeption Winter 2021 Aufgabe 2
📝❗ FiSi AP2 Konzeption Sommer 2022 Aufgabe 4d-e
📝❗ FiSi AP2 Konzeption Winter 2022 Aufgabe 3
📝❗ FiSi AP2 Konzeption Sommer 2023 Aufgabe 4
📝❗ FiSi AP2 Konzeption Winter 2023 Aufgabe 4a-b
Lösungen / Tools
💬❗ Welche Backuplösungen kennen Sie?
Welche Feature haben sie? (Wie) können die folgenden Anforderungen umgesetzt werden?
- Generationenprinzip, effiziente Backupstrategien
- 3-2-1-Regel
- WORM, Authentifizierung der Clients am Backupserver
- Verschlüsselung, Integritätsüberprüfung, Signaturen
- Automatisierung, Monitoring
- [0] Restic
- [1] Duplicity
- [2] Borgbackup
- [3] xcopy
„Überwachung“ / Monitoring
Ziele und Metriken
💬 Wofür wird Monitoring benötigt?
Welche Metriken kennen Sie?
- Verfügbarkeit, Wirtschaftlichkeit, Sicherheit, Skalierbarkeit, Administrierbarkeit
- Erkennung von Ereignissen vor Schadenseintritt
- Schnelle Benachrichtigung im Problemfall
- Ausfall von Diensten
- Ausfall von RAID-Platten
- Swap-Nutzung
- Erkennung von Tendenzen
- zunehmender Arbeitsspeicherverbrauch
- Speicherleak
- Netzwerklatenzen & Jitter
- zunehmender Arbeitsspeicherverbrauch
- Beobachtung, Kontrolle & Dokumentation von Angriffen
- Verbindungsaufbau/Minute
- Loginversuche/Minute
- Optimierung von Ressourcen
- Langzeitauswertung
- CPU-Auslastung (load)
- Erkennung von Mustern
- Auslastung nach Wochentag/Uhrzeit
- Langzeitauswertung
- Debugging
- Mit welchen Logdaten korrelieren unerwartete Metriken?
Komponenten
Check-Plugins / Exporters zur Erhebung der Metriken
- Konfiguration zu Überwachender Systemeigenschaften
- Geben Metriken meist numerisch (float/int) zurück
- Schwellwerte für
- Warnungen
- Kritische Zustände
z.B.
Datenbank
- sinnvoller Weise Round-Robin-Database
- Aggregation für nächst niedrigere Zeitauflösung
Dashboard
- Übersicht + Analyse
- Konfiguration
Notification
z.B. per Mail, SMS, IM, Chat, Pager, Desktop-/Push-Notification
Architektur
Datenerhebung
| Remote (Monitoringserver) | auf überwachtem „Client“ | |
|---|---|---|
| Wo wird Check ausgeführt? | für Netzwerkdienste | für Ressourcenauslastung |
| Wer triggert Aufruf zur Erhebung? | (x) | (x) |
| Wo werden Daten gespeichert? | (x) | |
| Wo/Wann werden Daten ausgewertet? | (x) |
Wie werden Daten übermittelt?
- Pull/Push
- Intervall
Rechtliche Fragen
- Datenerhebungsgrundlage + Speicherfristen
- Beweispflicht
Empfehlung
- Datensparsamkeit + begrenzte Speicherdauer bei Logdaten
- aggregierte (anonyme) RRD-Metriken
Lösungen
SNMP
Simple Network Management Protocol
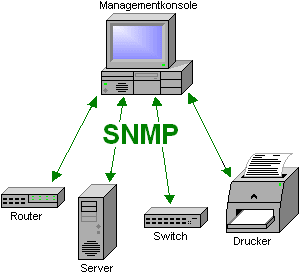
Management Information Base (MIB)
Netzwerkgeräte speichern ihre Konfiguration und Betriebsdaten lokal in einer „MIB“.
GET-REQUEST
Über das Netzwerk können die Informationen aus der MIB z.B. mittels „GET-REQUEST“ ausgelesen oder manipuliert werden
Sicherheitsprobleme
-
SNMP ist meist unverschlüsselt.
-
„Community-String“ wird als PSK verwendet.
Automatisierung von Administrationsprozessen
Images
- „Golden Image“
Skripte
Konfigurationsmanagementsysteme / Orchestration tools
Cloud orchestration tools
Vollständig deklarativ beschriebene Linux-Setups
Beispiele von Ergebnissen der Projektarbeiten in LF10b
Ansible
Beispiel
cd examples/ansible
ansible-playbook -i inventory.ini gather_facts_playbook.yml
Beispiele der FI23
Beispiel der FI22
Tutorial
Versionierung
Backups
Dateisystem-Snapshots
- ZFS
- btrfs
VM Snapshots
„Golden Image“
SCM (Source Code Management)
-> git
Planen der Konfiguration
Beschreibe Sie ihr Projekt (selbstdefinierte Aufgabenstellung).
mindestens 5 Sätze
Was sind ihre Ziele (persönliche Motivation)?
mindestens 5, besser 10 Stichpunkte
Welche Dienste sollen als Teil des Projektes integriert werden?
- Backup
- Monitoring
- …
Erstellen Sie eine grobe Übersicht, wie die Architektur des Projekes aussehen sollen.
Auf welcher Plattform soll das Projekt laufen? Welche Hardware wird benötigt? Welche Betriebsysteme werden genutzt?
Sollen einzelne Dienste virtualisiert werden? Falls ja, mit welchen Technologien?
Überlegen Sie für jeden Dienst, mit welcher Software er betrieben werden soll. Vergleichen Sie dafür alternative Softwarelösungen anhand geeigneter Kriterien.
Welche Recovery Time Objective (RTO) wollen Sie erreichen?
Welche Systemeigenschaften sollen vom Monitoring überwacht werden?
Habt Sie bereits Gedanken, wie eine spätere Automatisierung umgesetzt werden kann?
Erstellen Sie einen groben Zeitplan für die Umsetzung des Projektes.
Wer aus dem Team wird welche Aufgaben übernehmen?
Welche Anleitungen (bzw. Tutorials) soll genutzt werden? Welche sonstige Dokumentation könnte nützlich sein?
Wiederanlaufplan
SOL
Entwerfen Sie einen Wiederanlaufkonzept für das Serverprojekt, welches Sie in den nächsten Unterrichtstagen aufgesetzen möchten.
Machen Sie sich dafür zunächst grob Gedanken, welche Schritte zum neu Aufsetzen des Systems nötig sein werden.
- Welche Automatisierungslösung möchten Sie nutzen (ausprobieren)?
- Welche Backuplösung werden sie einsetzen?
Mittels des Wiederanlaufplanes (den Sie im späteren Laufe des Projektes vervollständigen dürfen) und den darin beschriebenen Daten (Konfiguration+Backups) muss es für andere ITler möglich sein, das Setup auf einem neuen System erneut aufzusetzen.
Was schätzen Sie, wie lange für die Wiederinbetriebnahme benötigt wird (RTO)?
Die SOL-Aufgabe darf als Gruppenarbeit gelöst und eingereicht werden. Die Abgabe soll möglichst per Link auf ein Git-Repository in ilias erfolgen.
Implementierung
Berücksichtigung betrieblicher Vorgaben und Lizenzierungen
Testverfahren
Wiederanlaufplan
Dokumentation von Ergebnissen
Docker
Kundenspezifische Rahmenbedingungen
Optimieren
Dokumentation
Projekte FI23
| Team | Monitoring | Backup | Automatisierung | Virtualisierung/Container | Bonus |
|---|---|---|---|---|---|
| Tablettenschrank Proxmox, Kubernetes | PM, CheckMk, … | PM | PM, Ansible | Proxmox, Kubernetes | <-- |
| boblukulus Pterodactyl | Prometeus | Borg | Ansible | Pterodactyl (Docker), VMware | <-- |
| itsso23 Win2025 | CheckMK | WinBackup | PowerShell, Ansible | Hyper-V | <-- |
| Graylog | Prometheus | Veeam | PowerShell, Ansible | Hyper-V | <-- |
| Amir | PRTG, WMI | Hasleo, Acronis | .bat | Hyper-V | <-- |
Optimieren
Bewertung
Backup
- Inkrementelle oder Differenzielle Backups
- Konfiguration des Monitoring wird gebackupt
- Ein Backup wurde erfolgreich zurückgespielt
- Backups werden automatisch erstellt
- Benachrichtigung, wenn automatische Erstellung von Backups fehlschlägt (optional mittels Monitoring)
Monitoring
- Läuft
- Ram-Auslastung wird überwacht
- verbleibende freie Festplatenkapazität wird überwacht
- Erfolgreiche automatische Erstellung von Backups wird überwacht
- Im Fehlerfall werden Benachrichtigungen „versendet“
Automatisierung
- Regelmäßige vollständige Updates gewährleisten
- Automatische Wiederherstellung möglich
- Lösung ermöglicht Review von Veränderungen (Change Management)
- Idempotente Anwendung der Konfigurationsverwaltung funktioniert fehlerfrei
- Mehrere Konfigurationen lassen sich miteinander kombinieren
- Ein einzelner Konfigurationsschritt kann einfach und sauber rückgängig gemacht werden
Organisatorische Maßnahmen
- Planung
- Dokumentation
- Versionskontrolle
- …
Bonus
- Virtualisierung, Containerisierung
- Dienste
- Skalierung
-
Weitere Maßnahmen zur Steigerung der Verfügbarkeit
- z.B. RAID, Netzwerkredundanz
Reflexion — SOL 21.11.-23.11. 2025
Aufgabe: Denken Sie darüber nach, wie Sie ihr Projekt aus LF10 weiter verbessern können. Fokussieren Sie sich dabei insbesondere auf Aspekte der IT-Sicherheit.
Frischen Sie ihre Kenntnisse aus aus LF4 auf.
Machen Sie sich Gedanken, ob Sie im Rahmen des Praxisprojektes von LF11 das Projekt aus LF10 weiterentwickeln oder ein neues Projekt beginnen möchten. Beschreiben Sie (kurz und knapp) Ihre Projektidee.
Vorschläge für Projekte LF11
AE
- Client-Server-Anwendung (z.B. Webanwendung mit Backend)
- Backend mit (SQL-)Datenbank
- (REST-)API
- Authentifizierung
- Absicherung gemäß BSI-Grundschutz, siehe Hinweise für AE
SI
- Endgerätesicherheit
- TLS
- Firewall
- Authentifizierung
- VPN
- Absicherung gemäß BSI-Grundschutz, siehe Hinweise für SI