Skalierbarkeit
❓❗ Welche Arten von Skalierbarkeit gibt es und in und welche davon möchten Sie in welchen Fällen nutzen?
📝❗ FiSi AP2 Konzeption Sommer 2023 Aufgabe 2b
Horizontale Skalierung (scale out) vs Vertikale Skalierung (scale up)
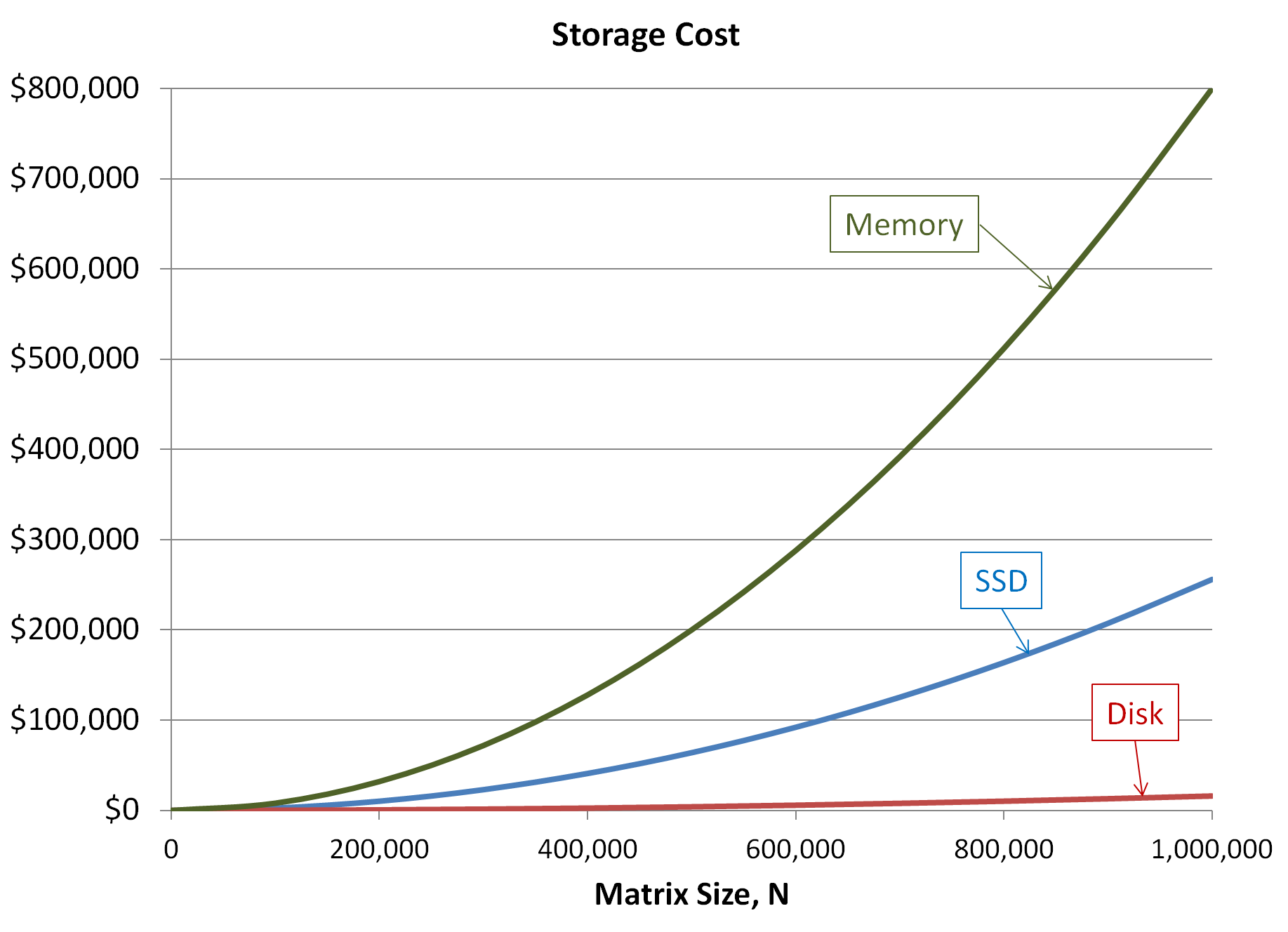
=> Wenn „doppelt so viel“ benötigt wird, kostet das meist deutlich mehr als das zweifache
(bei scale up)…
=> Warum nicht einfach „zweimal das einfache“ nutzen?
=> scale out! => commercial off-the-shelf
- Beispiele für Umsetzung von horizontaler Skalierungslösungen
- Einschränkung durch Kommunikation + SharedMemory
- Kurz und Knapp:
- CAP-Theorem




Beispiele für Umsetzung von horizontaler Skalierungslösungen
flowchart TB Skalierbarkeit --> Cluster Skalierbarkeit --> LoadBalancer Skalierbarkeit --> Anycast/Multicast
Einschränkung durch Kommunikation + SharedMemory
Grenzen der horizontale Skalierung:
- Verteilte Dateisysteme
- Verteilte Datenbankmanagementsysteme
- Uniform Memory Access (Symmetrisches Multiprozessorsystem) vs Non-Uniform Memory Access (Asymmetrisches Multiprocessing)
Die Parallele Effizienz von Algorithmen ist problemabhängig und ein eigenes Fachgebiet.
Für Details bitte die passende Vorlesung besuchen, die richtigen Bücher lesen, …
Oder sich von jemandem beraten lassen, der sich damit auskennt ;)
Probleme: Kommunikationsoverhead, Konsistenz, Cache-Kohärenz

Kurz und Knapp:
=> Wann immer möglich ist Horizontale Skalierung (scale out) meist deutlich günstiger als Vertikale Skalierung (scale up).
=> Horizontale Skalierung funktioniert dann gut, wenn:
- das Problem gut parallelisierbar ist
(Teilprobleme lose gekoppelt sind) - die Softwarearchitektur für diese Art von Problemen geeignet optimiert ist
=> daher ist schlaue Auswahl der Lösung sehr wichtig
=> Es gibt jedoch leider auch Herausforderungen, bei denen eine horizontale Skalierung schwierig bis unmöglich ist
CAP-Theorem
Das CAP-Theorem besagt, dass es in einem verteilten System unmöglich ist, gleichzeitig die folgenden drei Eigenschaften zu garantieren:
- Consistency (Konsistenz)
- Availability (Verfügbarkeit => akzeptabler Antwortzeiten)
- Partition Tolerance (Ausfalltoleranz)
Jedes Systemdesign kann nur maximal zwei der drei Eigenschaften garantieren.

AP
Consistency + Availability + Partition Tolerance
Wenn Verfügbarkeit und Ausfalltoleranz wichtig sind, kann keine Konstistenz gewährleistet werden.
Für viele Dienste reicht Eventual consistency.
Für diesen Anwendungsfall sind NoSQL-Datenbanken optimiert.
In diese Kategorie fallen die meisten „Cloud“-Dienste bzw. Internet-Dienste.
z.B. DNS, NTP, Mail, …
=> horizontale Skalierung ist möglich => kostengünstige Lösungen möglich
CP
Consistency + Availability + Partition Tolerance
z.B. Banking-Anwendungen
Konsistenz ist essenziell und es muss davon ausgegangen werden, dass einzelne Komponenten ausfallen.
=> In dem Fall wird akzeptiert, dass Dienste mal nicht zur Verfügung stehen (es darf länger dauern)
CA
Consistency + Availability + Partition Tolerance
Relationale Datenbankmanagementsysteme (RDBMS) sollen Konsistent sein (ACID). Wenn auch Verfügbarkeit benötigt wird (meistens), dann ist keine Partitionstoleranz möglich. Wenn einzelne (Primary) Knoten ausfallen, muss ein anderer Knoten die Funktion übernehmen können und dafür den letzten Zuständ des Primary kennen. Dafür muss der Primary jeden Schreibzugriff an seine potentiellen Ersatzknoten kommunizieren, bevor eine Transaktion als erfolgreich commited abgeschlossen werden kann.
Wir benötigen also schnelle Kommunikation und Cache-Kohärenz zwischen den Knoten…
=> Scale Up
=> teuer